Introducing Tensormesh Beta 2: One-Click LLM Deployment, New UI & Real-Time Cost Savings

Tensormesh is an AI inference optimization company that never charges you twice for cached tokens, making AI applications faster and dramatically cheaper to run anywhere.
We are excited to announce the launch of Tensormesh Beta 2, a complete redesign of our platform focused on simplicity, speed, and visibility. After listening to feedback from our beta community, we rebuilt the experience from the ground up to make deploying and managing LLMs easier than ever.
Ready to try it? Access the platform at app.tensormesh.ai and join our Slack community to chat with the team directly.
1. New User Interface with One-Click Deployment
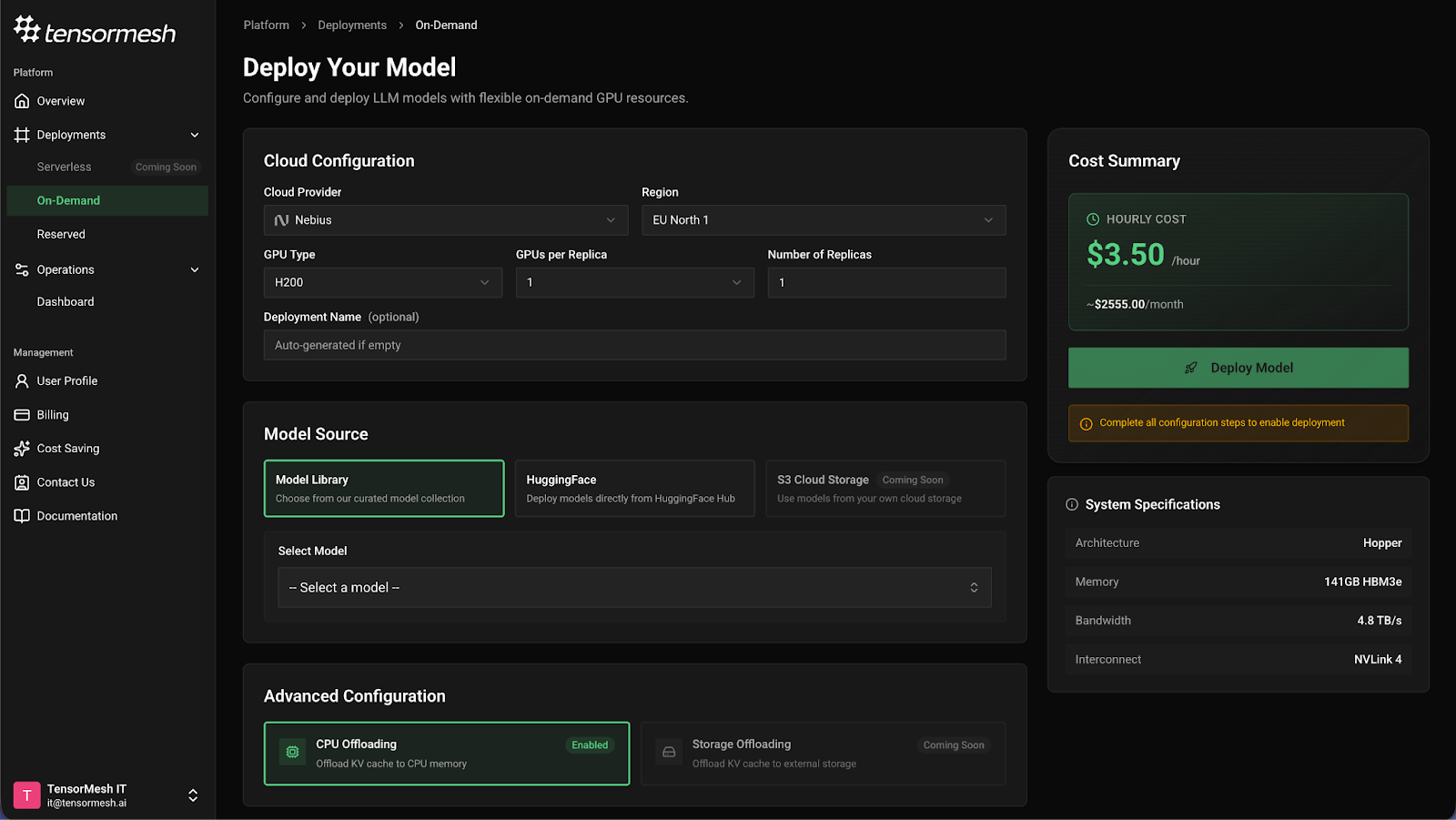
We have completely reimagined the Tensormesh interface with user experience as our top priority. The new design eliminates unnecessary scrolling and complexity—you can now deploy an LLM with a single click.
Why this matters:
The deployment process is now intuitive and fast. Select your GPU provider, choose your model, configure advanced settings if needed, and deploy. No more navigating through multiple screens or complex configuration steps.
2. New Overview Dashboard with Test Interface
Your command center has received a major upgrade. The new Overview Dashboard features Quick Actions including a conversational chatbot with a test interface that simulates concurrent usage through batching.

In practice:
You can now generate synthetic cache hit rates before committing to a full deployment. This allows you to validate performance expectations and optimize your configuration upfront. All deployment and management tasks are now accessible in a single click from the dashboard.
3. New Pre-Loaded LLM Support
Deploying the latest models just got dramatically faster. We have pre-loaded support for trending LLMs so you can spin them up instantly without waiting for downloads:
Qwen3 Family:
- Qwen3-30B
- Qwen3-235B
- Qwen3-Coder-30B-A3B-Instruct
Mistral:
- Devstral-2-123B-Instruct-2512

The benefit:
No more waiting for model downloads. The latest trending models are ready for immediate deployment, letting you experiment and iterate faster.
4. Reserved Deployment Support
We have introduced a new deployment option for teams that need dedicated GPU capacity at predictable pricing.
What does this mean for you?
Reserved deployments allow you to lock in dedicated GPUs at a discounted rate with a time commitment. This is ideal for production workloads where you need guaranteed capacity and want to optimize costs over time.
5. Enhanced Deployed Model Dashboard
Visibility is essential for optimization. The new Deployed Model Dashboard provides an extensive view of your deployment information including ready-to-use curl samples and two new critical metrics:
GPU Compute Utilization This metric shows exactly how hard your GPU hardware is working. Monitoring GPU utilization helps you right-size your deployments and identify opportunities to increase efficiency or scale capacity.
KV Cache Usage Ratio This measures how effectively your deployment is utilizing the KV cache. A higher ratio indicates better cache efficiency, which directly correlates with cost savings and improved latency.
Why this matters:
These metrics give you the observability needed to understand and manage your deployed models effectively. You can now make data-driven decisions about scaling, optimization, and resource allocation.
6. User Management & Cost Tracking
The new User Management hub puts your spending and savings in one place:
- Spending breakdown by day, week, and month
- Cost savings tracker based on KV Cache Hit utilization
- Simple contact options via form or live Slack channel
- In-app notifications to keep you informed
The result:
You now have complete visibility into your AI infrastructure costs and can see exactly how much you are saving through Tensormesh's KV Cache optimization. Reaching the team is now just one click away.
Coming Soon
We are not slowing down. Here is what is on our roadmap:
Infrastructure Expansion:
- Serverless Deployment for pay-per-request pricing
- Autoscaling from 0 to 8 replicas
- Multi-provider support: AWS, Google Cloud, Azure, and CoreWeave
- HGX B200 GPU support for next-generation performance
New Model Support:
- DeepSeek 3.2
- Moonshotai Kimi-K2-Instruct
- GLM-4.7-Flash (zai-org)
Account Updates
To improve platform security and service quality, we've made a few changes to how accounts work:
- Credit card required for deployment: A valid credit card is now required to deploy models.
- X-User-Id header mandatory: All API requests must include the X-User-Id header.
- $100 credit refresh: Users who reach zero balance can receive a new $100 credit after completing a short feedback survey.
Try Tensormesh v2 Today
To explore these new features, visit your Tensormesh dashboard.
Are there features you would like us to add to our product?
Feel free to reach out to us via:




































